Twitter increased the character limit to 280 for most countries in November of 2017. We quickly followed suit and enabled the functionality in our composer and browser etensions. In this analysis we’ll take a look at a random sample of tweets scheduled with Buffer in the past couple of years to see if people have been taking advantage of the increased character limit.
We’ll gather the tweets by querying Buffer’s updates table, but we could also use the handy rtweet package to gather the tweets. We’ll begin by gathering a random sample of one million tweets sent in 2016 and 2017.
select
id
, created_at
, sent_at
, date_trunc('month', sent_at) as sent_month
, was_sent_with_buffer
, text
, len(text) as length
from dbt.updates
where profile_service = 'twitter'
and (not has_photo or has_photo is null)
and (not has_multiple_photos or has_photo is null)
and (not has_video or has_photo is null)
and sent_at >= '2016-01-01'
and sent_at < '2018-01-01'
order by random()
limit 1000000We need to do a bit of tidying before we draw any conclusions. We first want to determine if the tweet contains a link. If it does, we will remove the full-length url and replace it with a shortened one that contains the number of characters that Twitter’s link shortener produces. We’ll use the stringr package to extract the URL.
According to this article, all links, regardless of their actual length, take up 23 characters in Twitter. That’s a good enough approximation for us, so let’s try to replace all url’s with a 23 character made up url.
# define url regex pattern
url_pattern <- "http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+"
# extract url
tweets$url <- str_extract(tweets$text, url_pattern)
# get the year, replace urls, and calculate length
tweets <- tweets %>%
filter(was_sent_with_buffer) %>%
mutate(year = as.factor(year(sent_at)),
sent_month = as.Date(sent_month, format = '%Y-%m-%d'),
text_updated = gsub(url_pattern, "https://t.co/x6yvMQC1vG", text)) %>%
mutate(length = nchar(text_updated))Let’s glimpse the dataset that we have now.
# glimpse tweets
glimpse(tweets)## Observations: 769,687
## Variables: 10## Warning in as.POSIXlt.POSIXct(x, tz): unknown timezone 'default/America/
## New_York'## $ id <chr> "585ff590ae69734266970527", "595239dd2633...
## $ created_at <dttm> 2016-12-25 16:36:32, 2017-06-27 10:56:29...
## $ sent_at <dttm> 2016-12-25 16:36:45, 2017-06-27 10:56:35...
## $ sent_month <date> 2016-12-01, 2017-06-01, 2017-06-01, 2017...
## $ was_sent_with_buffer <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE,...
## $ text <chr> "Jesus came to bring peace. He came to be...
## $ length <int> 94, 76, 23, 91, NA, 275, 140, 59, 90, 100...
## $ url <chr> NA, NA, "http://buff.ly/2sIFx9j", "http:/...
## $ year <fctr> 2016, 2017, 2017, 2017, 2017, 2017, 2017...
## $ text_updated <chr> "Jesus came to bring peace. He came to be...Looks good so far!
Data cleaning
There are a few things we should check before making any inference. First let’s check tweets that have null values in the length column.
# view tweets with NA as length
tweets %>%
filter(is.na(length)) %>%
head()## id created_at sent_at
## 1 5a20aee2e47d2b3073c80136 2017-12-01 01:22:42 2017-12-01 03:22:00
## 2 5a08a327f8594ccb736f1074 2017-11-12 19:38:15 2017-11-13 06:15:05
## 3 5a355082fc7ffc022a2a2395 2017-12-16 16:57:38 2017-12-17 07:14:00
## 4 596da62014bfa12032e4a153 2017-07-18 06:09:36 2017-07-19 06:07:06
## 5 5a35efd99363921642c823fa 2017-12-17 04:17:29 2017-12-20 01:40:09
## 6 59d75e5634e95d440812a4cc 2017-10-06 10:43:34 2017-10-06 15:36:04
## sent_month was_sent_with_buffer text length url year text_updated
## 1 2017-12-01 TRUE <NA> NA <NA> 2017 <NA>
## 2 2017-11-01 TRUE <NA> NA <NA> 2017 <NA>
## 3 2017-12-01 TRUE <NA> NA <NA> 2017 <NA>
## 4 2017-07-01 TRUE <NA> NA <NA> 2017 <NA>
## 5 2017-12-01 TRUE <NA> NA <NA> 2017 <NA>
## 6 2017-10-01 TRUE <NA> NA <NA> 2017 <NA>There are around 82 thousand of these tweets, and, to be honest, I don’t know what they are. I think that we can go ahead and remove them from the dataset.
# remove NAs
tweets <- tweets %>%
filter(!is.na(length))Next let’s look at tweets with over 140 characters that were sent before November 2017.
# look at tweets with > 140 characters
tweets %>%
filter(year == '2016' & length > 140) %>%
select(text_updated, length) %>%
head()## text_updated
## 1 https://t.co/x6yvMQC1vG~r/TheGlobalMuslimBrotherhoodDailyWatch/~3/u08D2Wtnbb0/ RECOMMENDED READING: “Double Games Of The #UK #MuslimBrotherhood”
## 2 https://t.co/x6yvMQC1vG~r/TheGlobalMuslimBrotherhoodDailyWatch/~3/dEeOSbPSzdc/ FEATURED: US #MuslimBrotherhood Coalition Announces Formation Of New Global Body; #UK #MuslimBrotherhood Leaders in…
## 3 .@rdesai7: My Happy #AlohaFriday song pick is (once again) Jack Johnson/Hawaiian Slack Key Kings "Better Together" \U0001f33a\U0001f334\U0001f3c4\U0001f3fe♀️\U0001f44f\U0001f3fd\U0001f3b6❤️️https://t.co/x6yvMQC1vG…
## 4 RankBrain Judgment Day: four SEO tactics you’ll need to survive | Search Engine Watch https://t.co/x6yvMQC1vG|EMAIL_B64|*&utm_source=Search+Engine+Watch&utm_campaign=9630ee1ecb-23_03_2016_NL&utm_medium=email&utm_term=0_e118661359-9630ee1ecb-17050349
## 5 RT @BBCNews: Boris Johnson says "fat cats" who back Remain know nothing of hospital waiting listshttps://t.co/x6yvMQC1vG #EUref https://t.co/x6yvMQC1vG…
## 6 RT @GreysABC Chandra Wilson knows what she's talking about #GreysAnatomy https://t.co/x6yvMQC1vG#.umvh1z9l7 #SocialMediaMarketing #SocialMediaPromotion
## length
## 1 144
## 2 195
## 3 152
## 4 249
## 5 152
## 6 151We can see clearly here that we did not fully clean up the links in the tweets. We can also see that some tweets contain multiple links. Let’s try another regex pattern to clean up the URLs.
# replace string starting with "http" and followed by any number of non-space characters
replace_url <- function(x) gsub("http[^[:space:]]*", "https://t.co/x6yvMQC1v2", x)
# replace tweets in dataframe
tweets <- tweets %>%
mutate(text_updated = replace_url(text_updated)) %>%
mutate(length = nchar(text_updated))Now let’s take another look at tweets with over 140 characters.
# look at tweets with > 140 characters
tweets %>%
filter(year == '2016' & length > 140) %>%
select(text_updated, length) %>%
head()## text_updated
## 1 RT @worldofabe: Need talent? Come see me about the Free Agent pilot at the #GC2020 Innovation Fair tomorrow! https://t.co/x6yvMQC1v2 https://t.co/x6yvMQC1v2
## 2 RT @ConWayFor: From @cllrjoeporter: Let’s all now embrace Brexit and become an even greater global leader https://t.co/x6yvMQC1v2 https://t.co/x6yvMQC1v2
## 3 .@rdesai7: My Happy #AlohaFriday song pick is (once again) Jack Johnson/Hawaiian Slack Key Kings "Better Together" \U0001f33a\U0001f334\U0001f3c4\U0001f3fe♀️\U0001f44f\U0001f3fd\U0001f3b6❤️️https://t.co/x6yvMQC1v2
## 4 RT @BBCNews: Boris Johnson says "fat cats" who back Remain know nothing of hospital waiting listshttps://t.co/x6yvMQC1v2 #EUref https://t.co/x6yvMQC1v2
## 5 RT @OficialCentro #Boletín244 Bachea Concejo Municipal 31 calles de 19 localidades de Centro. Ver https://t.co/x6yvMQC1v2 https://t.co/x6yvMQC1v2
## 6 #GreenImperialism https://t.co/x6yvMQC1v2 The Challenge: https://t.co/x6yvMQC1v2 https://t.co/x6yvMQC1v2 https://t.co/x6yvMQC1v2 https://t.co/x6yvMQC1v2
## length
## 1 156
## 2 153
## 3 151
## 4 151
## 5 146
## 6 152Many of these are only a few characters above 140, so let’s just leave it for now. :)
Tweets per month
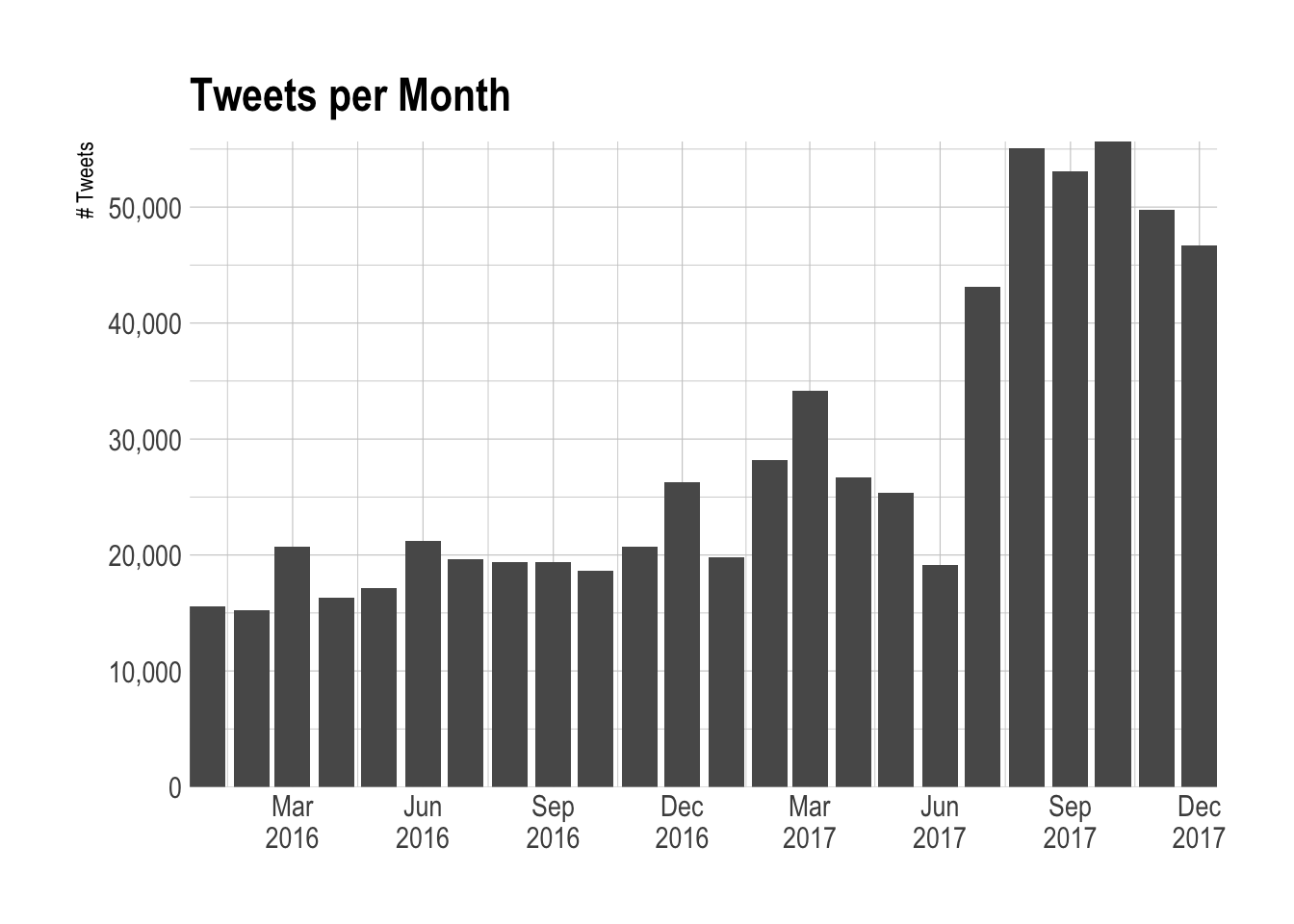
Let’s try to get a better understanding of the dataset. First, we’ll plot the number of tweets sent in each month. We can see that many of the tweets in our dataset were sent during the past six months. Perhaps the sample of tweets we retreived were not randomly selected. We’ll power through it for now.
Distribution of tweet length
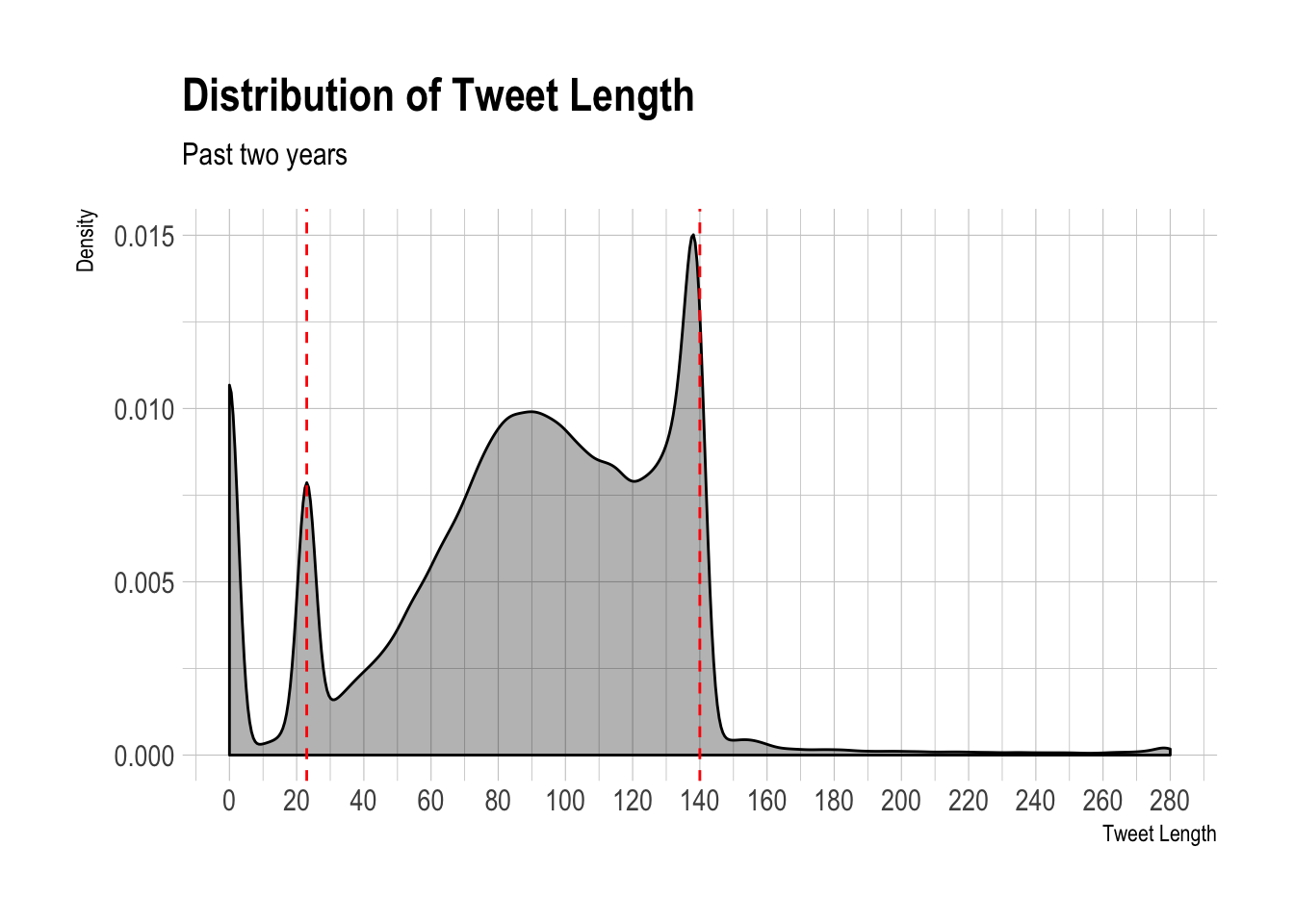
Let’s plot the overall distribution of tweet length in our dataset. We can see a spike around 0 characters – I’m imagining short emoji tweets. We also see a spike around 23 characters, which represents tweets that only contain links. For longer tweets, there is a local maximum around 88 characters, and a global maximum right under the 140 character limit. We can see a short, thin tail of tweets over 140 characters.
Now let’s plot the how the distribution of tweet length has changed over time. To do this, we’ll create something called a Beeswarm Plot. Beeswarm plots are a way of plotting points that would ordinarily overlap so that they fall next to each other instead. In addition to reducing overplotting, it helps visualize the density of the data at each point, while still showing each data point individually.
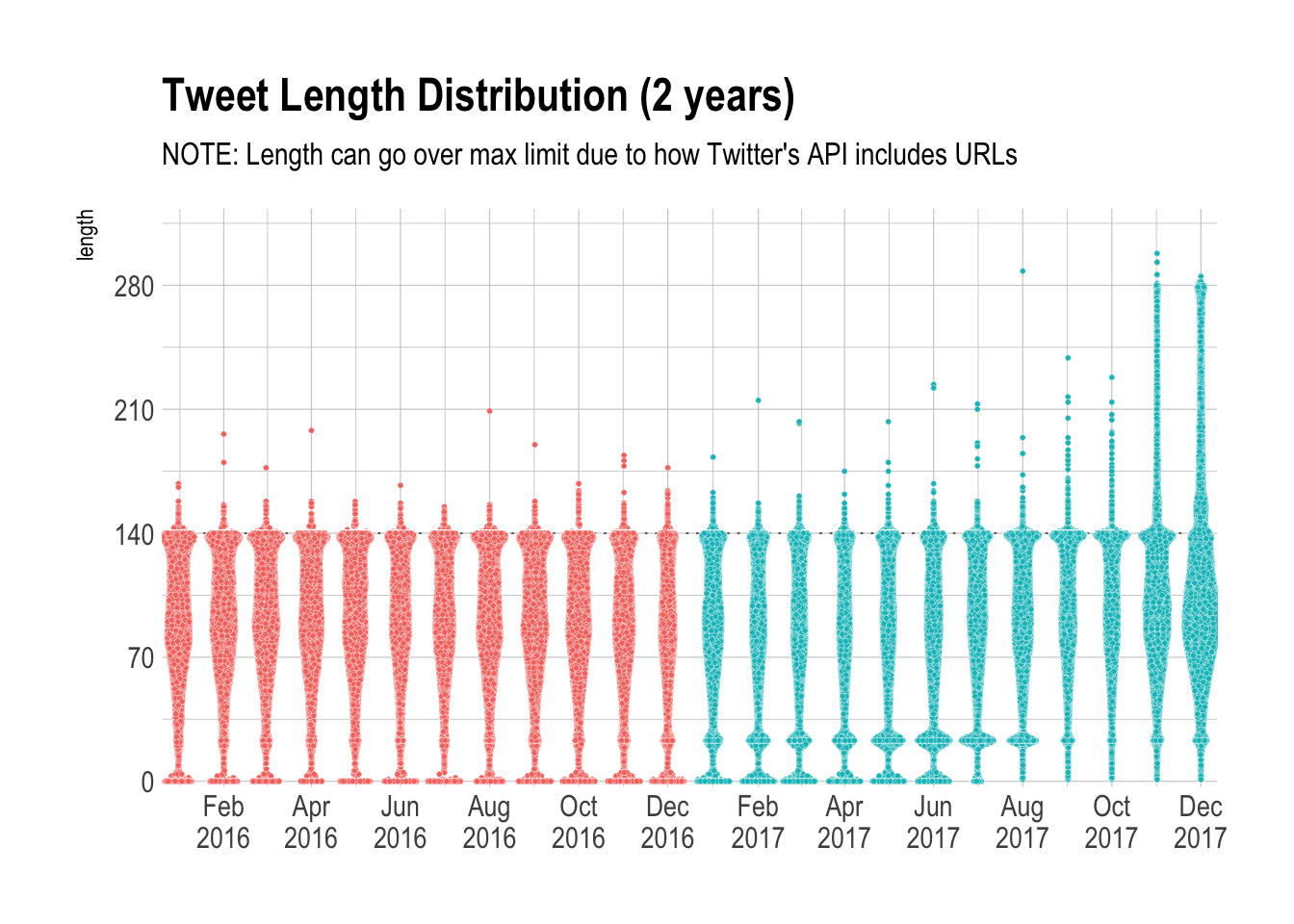
We can see that folks do seem to have been taking advantage of the new character limits in November and December. Interestingly, the proportion of tweets only containing links seems to have increased in early 2017, before decreasing towards the end of the year. I wonder why this might be. Do you think the trend of an increasing proporiton tweets over 140 characters will continue into 2018, or will people stay in their comfort zone of ~90 characters?
I’d love to hear what you think! Thanks! :)